Expectation-Maximization (EM) algorithm part II (EM-PCA)
machine learningEM algorithmPCAgenomics
In this section, we will explore another practical application of the EM-algorithm to speed up the computation of PCA. This section assumes the readers have already read my introduction part of EM algorithm.
Classical PCA
In classical PCA, given an input matrix X∈RN×M (In genetic settings, N can be the number of individuals, and M be the number of SNPs), the goal is to find an orthonormal matrix W∈Rm×K containing K orthonormal vectors; and the corresponding scores (weight) along each vector z∈RK, such that each individual Xi∈Rm can be reconstructed using x^i=Wzi with the minimum error. Mathematically, we are trying the minimize:
J(W,Z)=N1∣∣X−ZWT∣∣F2
Under the constraint that W is an orthonormal matrix, the PC scores for each individual are therefore uncorrelated. Moreover, it can be proved by induction that the orthonormal matrix W is the eigenvectors corresponding to the top-K largest eigenvalues, which implies it captures the top-K variance when projecting X into the lower dimensional orthonormal subspace.
EM PCA
If we treat the dimensional reduction method as a probabilistic model, then the score matrix Z becomes a probabilistic distribution, and suppose we have the following assumptions:
Underlying latent variable has a Gaussian distribution
There is a linear relationship between latent and observed variables
Isotropic Gaussian noise (covariance proportional to an identity matrix) in observed dimension
Then we can set up the model as
x=Wz+μ+ϵP(z)=N(μ0,Σ)P(x∣z)=N(Wz+μ0,σ2I)
Notice here we can assume μ0=0 and Σ=I without losing generality, since if they are not, we can always find another W′=WU such that Uz∼N(0,I).
Then the marginal probability of x can be expressed as
We can simplify the problem by standardizing our dataset X so that μ=0. We, therefore, complete the setup of a typical EM algorithm.
In E-step, we compute
σ→0limp(Z∣X)=WT(WWT)−1XT
If σ=0, the results would become probabilistic, in which case we don’t discuss. Notice that WWT is an m×m matrix, which takes O(m3) to compute the inverse. We instead cleverly apply the matrix inverse property to transform WT(WWT)−1 to (WTW)−1WT, which reduces the inverse computation to O(K3), so that
and by taking the partial derivative for W, we get
W^=XZT(ZZT)−1
We thus complete the construction of the EM-PCA algorithm. Notice the complexity of the EM-PCA algorithm is dominated by O(TKmn), and T is the number of iterations. This algorithm is linear regarding sample size and feature dimension, therefore bringing great advantage when the reduction dimension K≪m and K≪n.
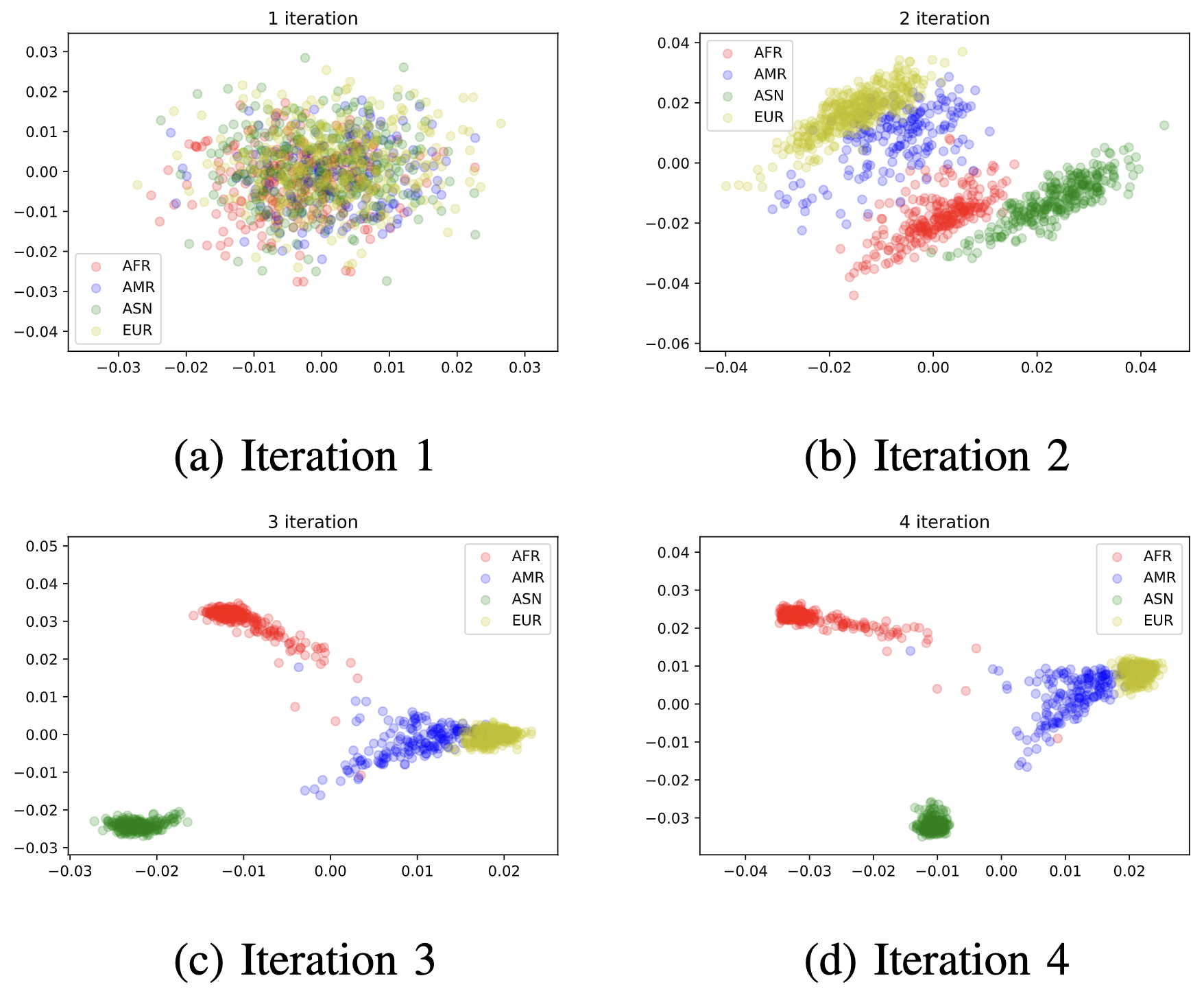
Experimental Results
Now let’s apply the algorithm to the 1000 Genome dataset to see how well the algorithm performs. As can be easily seen, EM-PCA has a fast convergence rate with a small runtime complexity.
References:
Murphy, Kevin P. Machine learning: a probabilistic perspective. MIT press, 2012.